Data Problems
The limiting factor of this project has been the data collection process. We created the data collection pipeline but built in some crippling factors. These mainly have to do with the format of our data. To explain these problems let’s look at the data layout:
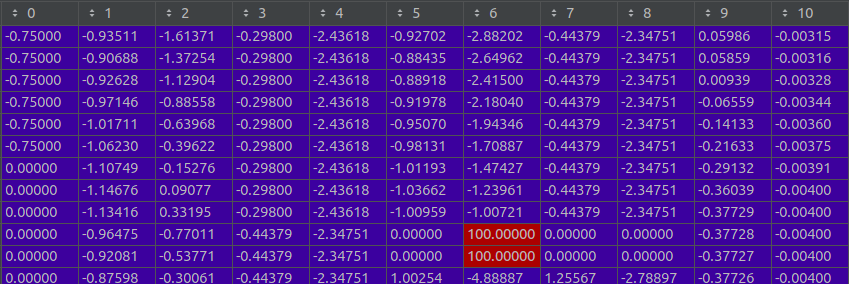
There are a couple interesting things that can be seen in this dataset.
- The first thing you can see is the outliers. These are in the two columns that encode the [x,y] position of the ball (shown in red). We made the decision to fill this data with large values for when there is only one ball present.
- The other interesting thing is the presence of negative values in the positions of the ball, this indicates that the balls are moving past the robot and being recorded
- The other interesting behavior (although not showcased in this data) is that the order of the balls in the data can actually switch, depending which is closer
All of these points translate into making the dataset difficult for the neural net to learn. This really points to the fact that to have more success with this project the data needs to be represented in a better way.
Network Analysis
Since our output was continuous, our models were constantly changing, and our model inputs were constantly changing, we struggled to produce detailed analyses of all of the different networks and approaches that we implemented or attempted. The continuous output makes it so that we can’t easily measure accuracy without first defining what accuracy looks like in this context and implementing code that measures that accuracy. If our output were discrete categorization, then measuring accuracy would be simple as we would just need to count the number of times the network categorized a set of inputs correctly, With our continuous output, we need to determine what kind of range of output is acceptable as “close enough”, and because we’re using imitation learning, we also need to determine whether we want to measure accuracy relative to what a human would have input for a certain case, as humans can also make mistakes here.
The fact that our models and model inputs were constantly changing made data wrangling and model wrangling difficult as small changes in one part of pipeline needed to be echoed throughout the pipeline. This was also due to the fact that we were working with our tensorflow pipeline and pytorch pipeline in parallel, making it so that we needed to maintain a different pipeline for each library as well.
Were we to approach this problem again, we likely would have approached it bottom-up, starting with the simplest network we could, analyzing the results carefully, and moving forwards from there. We also would have invested more effort into a versioning system to help us keep track of all of our models so that we could keep the element of parallelized exploration without also having to constantly adjust our pipelines to accommodate the new networks.