Looking at the gifs on our project homepage, it’s pretty clear that our robot has attempted to emulate human reflexes. In this blog post, we take a closer look, and try to understand why this behavior came to be.
It would be difficult to visualize a more complicated neural network with several layers to understand the basis behind the decision making for our model, so in this post, we take a closer look at two different models: one net has only 1 fully connected layer with one output, while the other net has why. For both of these models, the only input data is the dodgeball’s relative position (we’ll refer to this as px and py) and velocity (denoted as vx and vy) to the robot.
Let’s start by taking a look at the results from each model
1-Layer
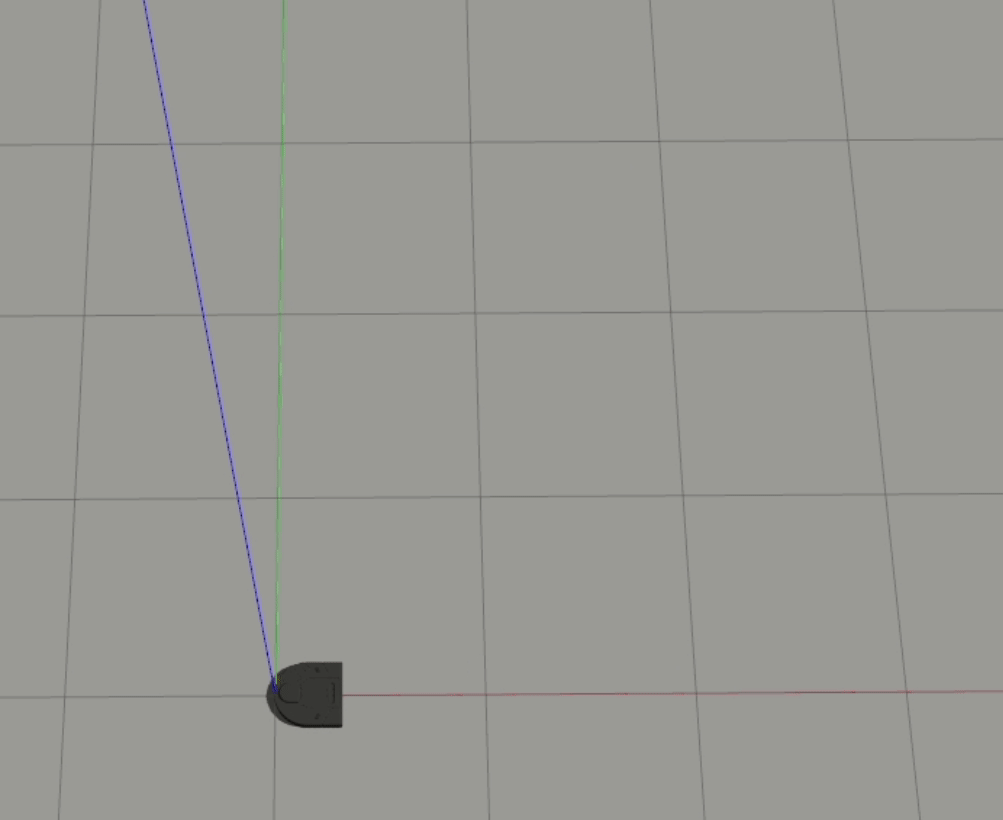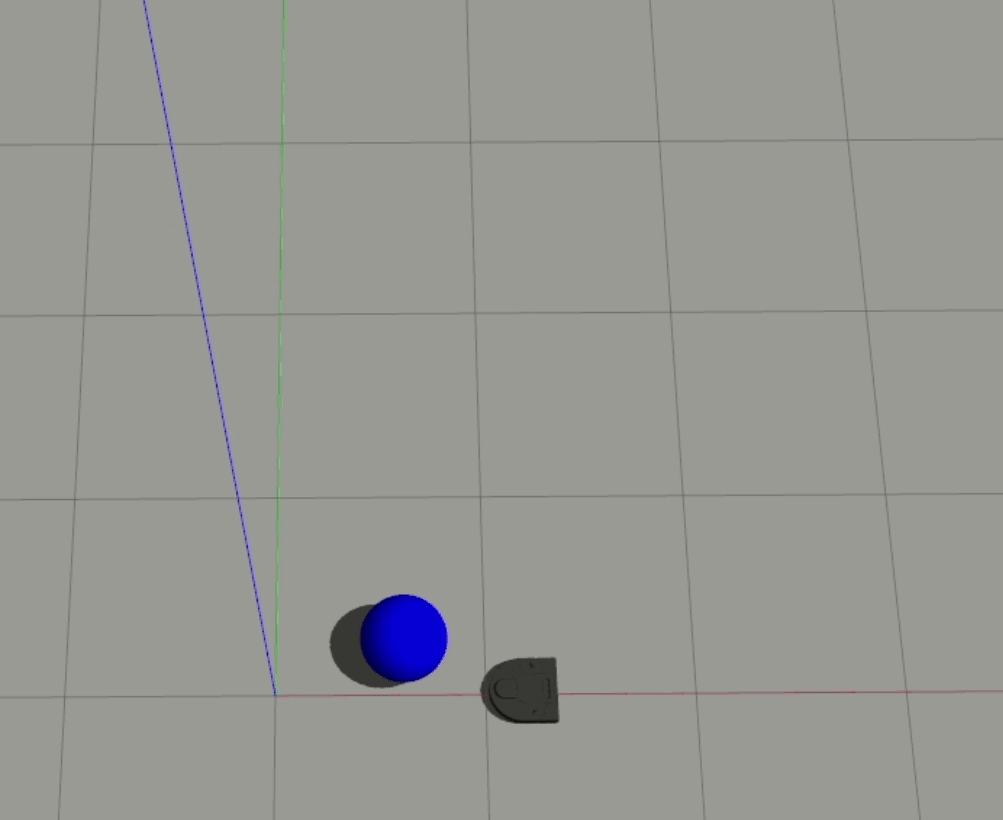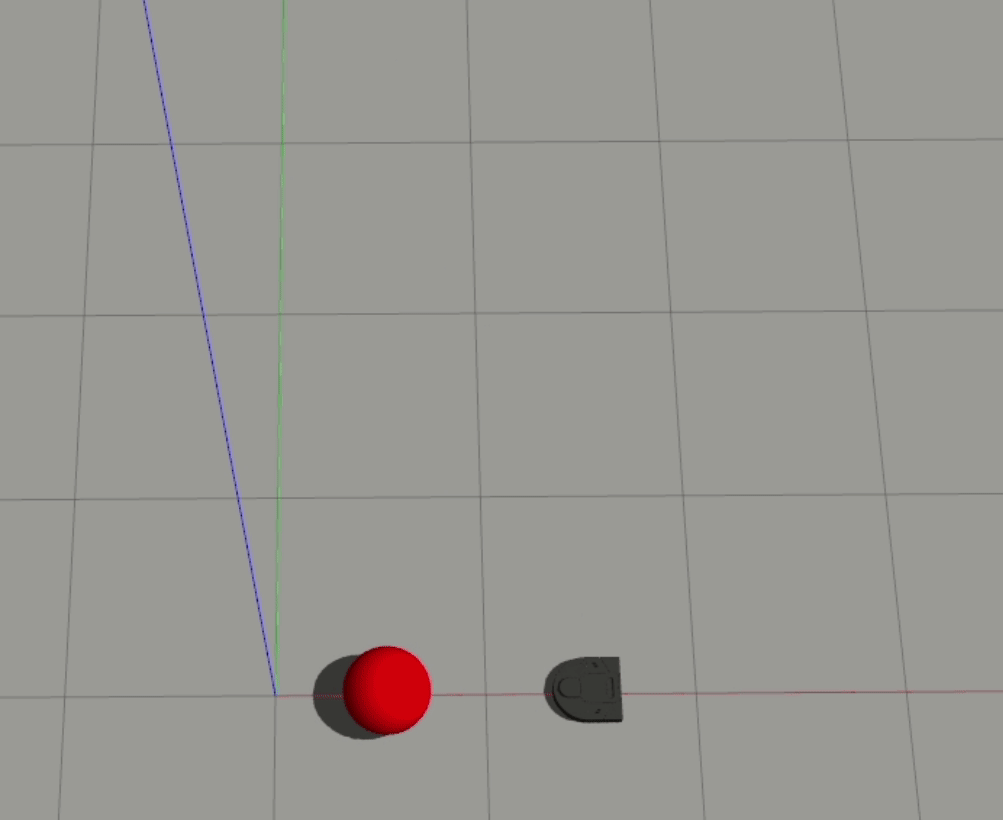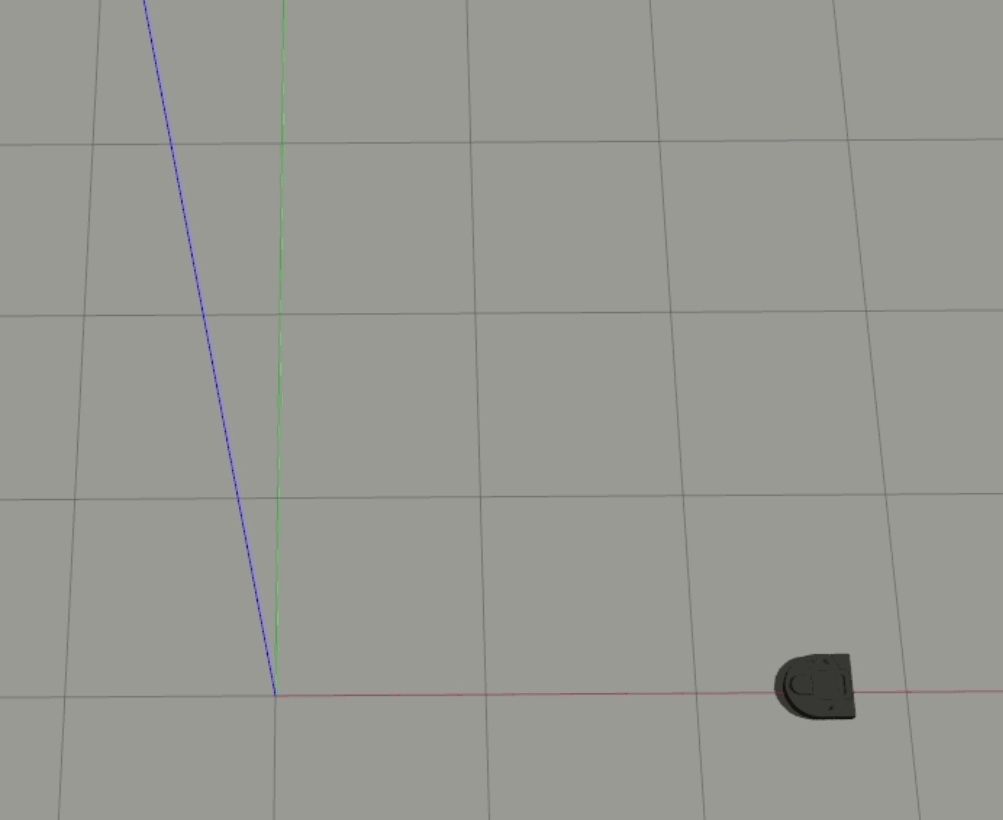
2-Layer
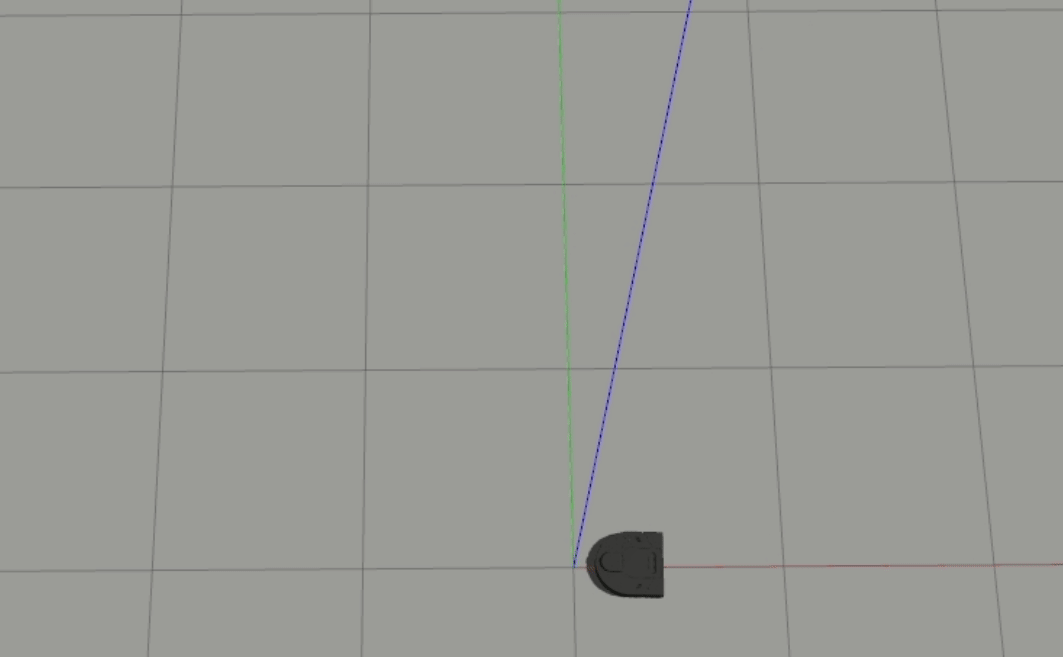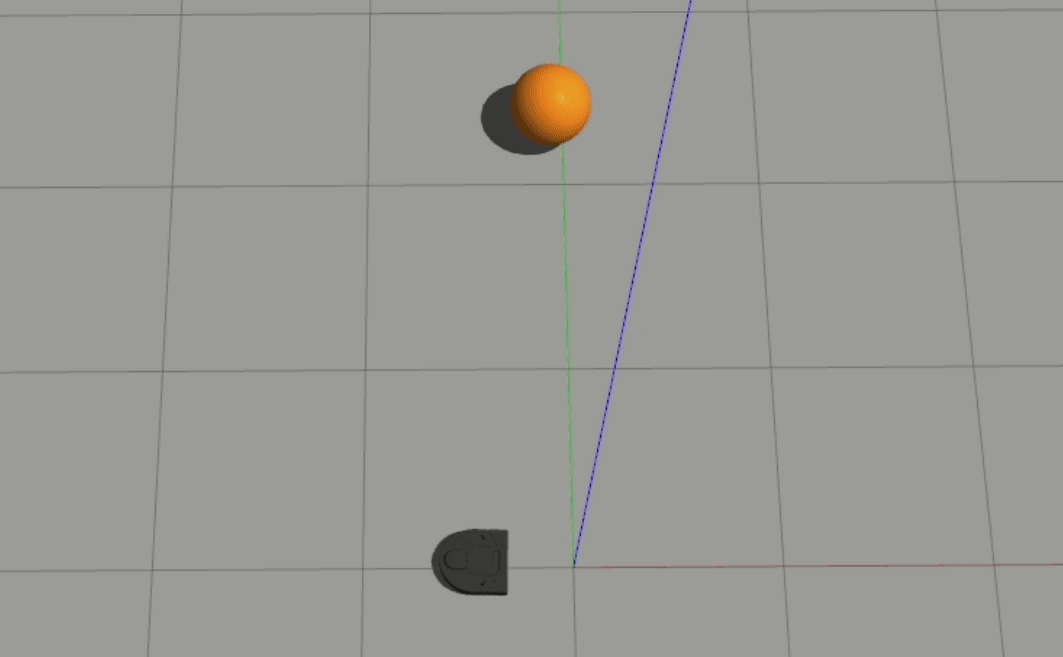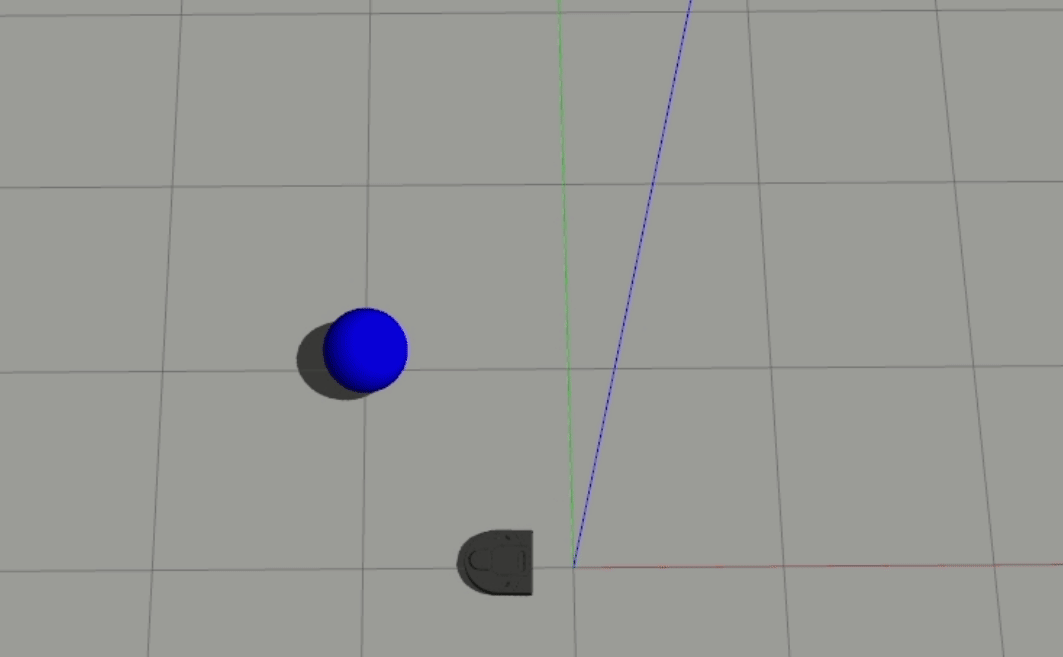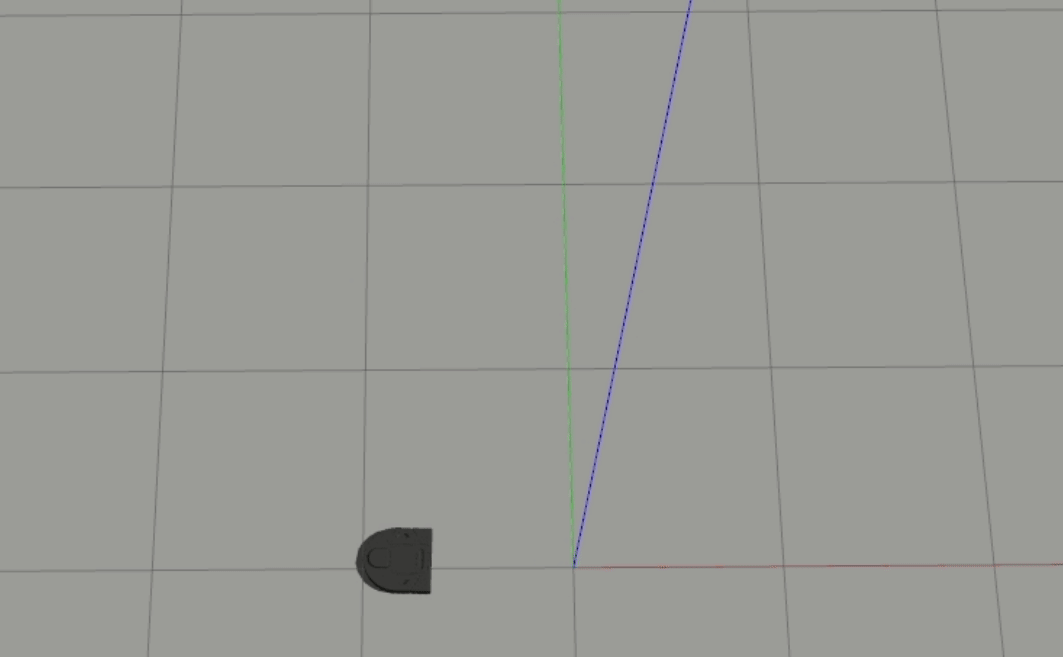
Generally, the 2-layer model performed a bit better than the 1-layer model, and the robot’s output behavior is visibly different between the two - the 1-layer model seems to move at more or less a constant magnitude of velocity, while the 2-layer model is clearly nonlinear and seems to have learned how to accelerate.
It’s also interesting to note that both models were able to imitate human reflexes in addition to learning that we wanted it to dodge the balls. It’s difficult to get an intuitive sense of exactly how this is computed in the two-layer case, but we can look at the weights from the one-layer case to get a sense of how the network encoded this behavior. The weights for the 1-layer case were:
[-1.2466, 0.2136, 0.0509, -0.0623, -0.7231]
px py vx vy bias
Interestingly enough, these output weights do also tell that story - py’s average value was approximately 3 when the balls were really far away while 0 meant that the robot was about to get hit. It’s worth noting that 3*0.2136 (py weight) approximately equals 0.7231 (magnitude of the bias term), which means that when the ball is far away the bias attempts to negate the effect of the y position. However, as the ball gets closer, the signal’s magnitude increases, encouraging the robot to move. In this case, it chose to go left (the bias term is negative), which is likely indiciative of the fact that the dataset contained more left-moves than right-moves.
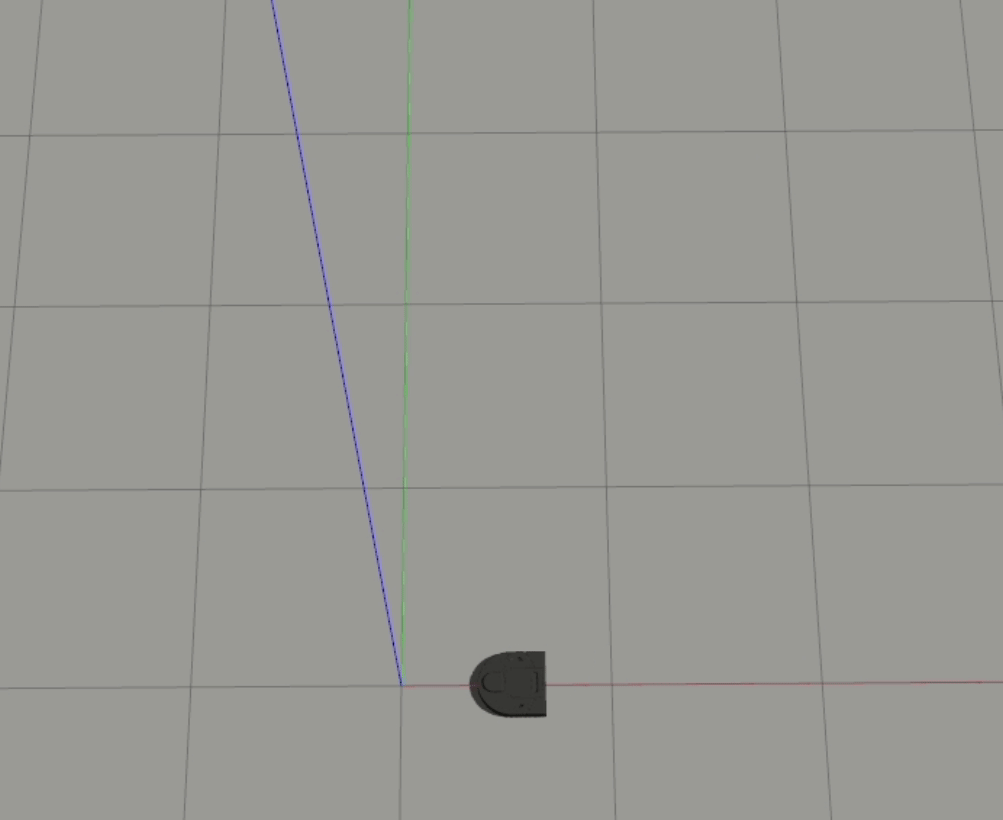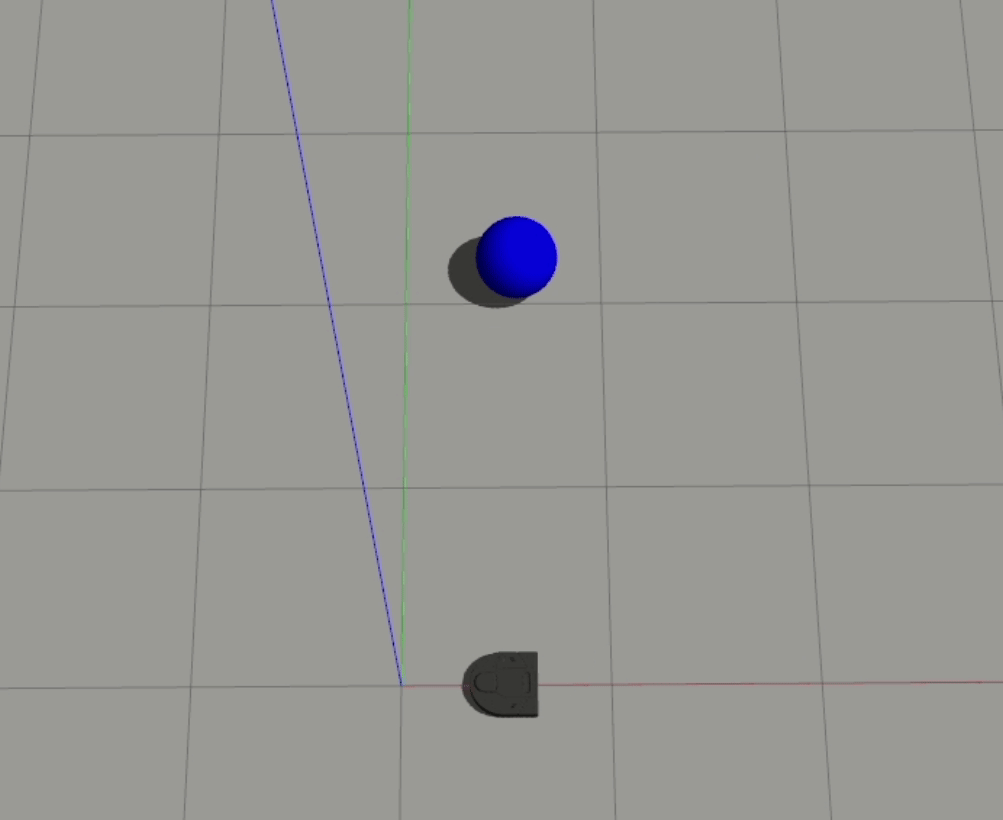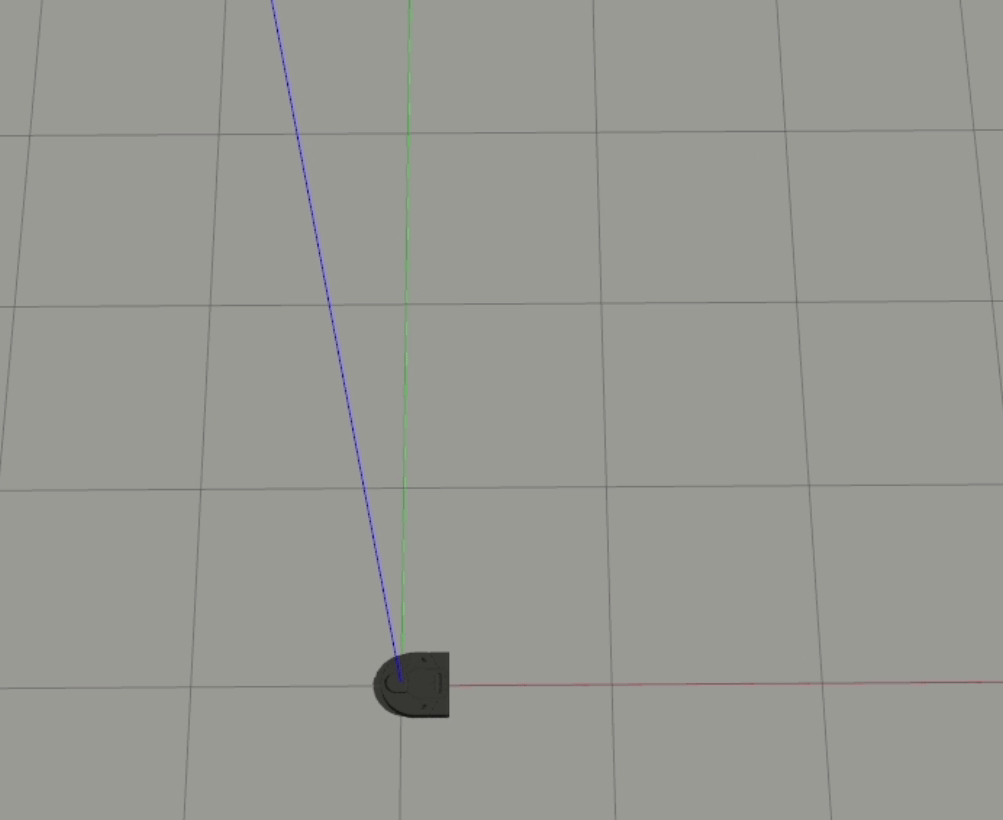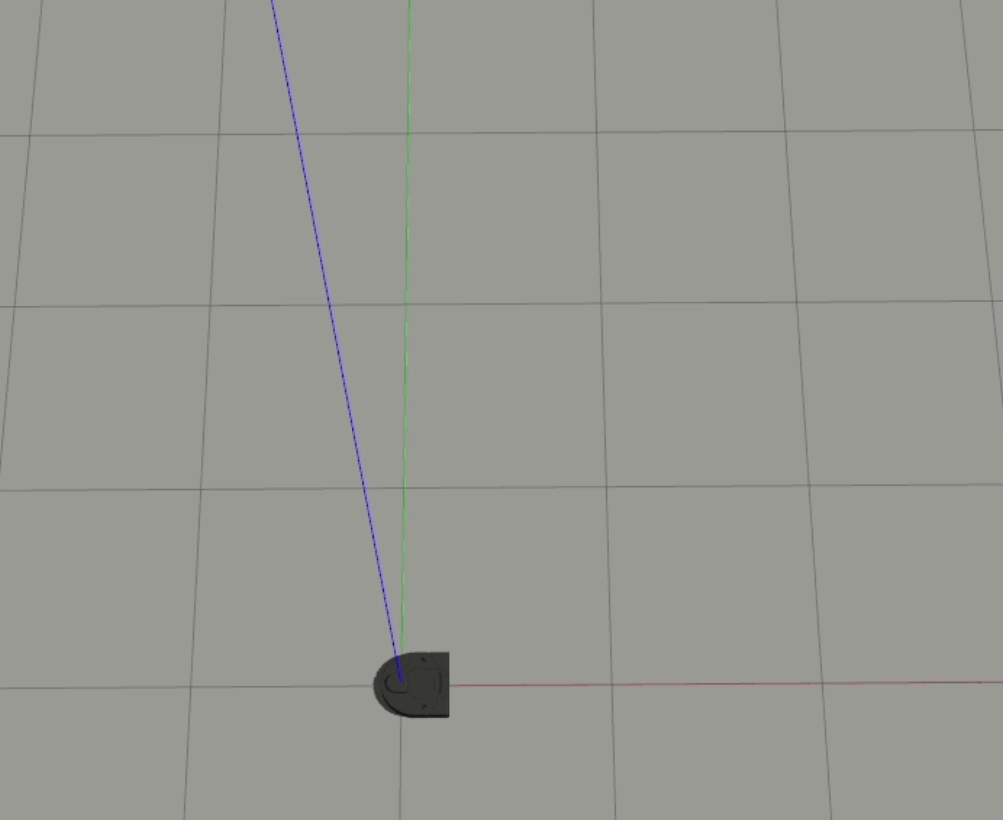
These output weights also tell the story of another interesting behavior - the fact that the robot doesn’t handle balls aimed right at it very well. This looks a bit like this:
1-Layer
2-Layer
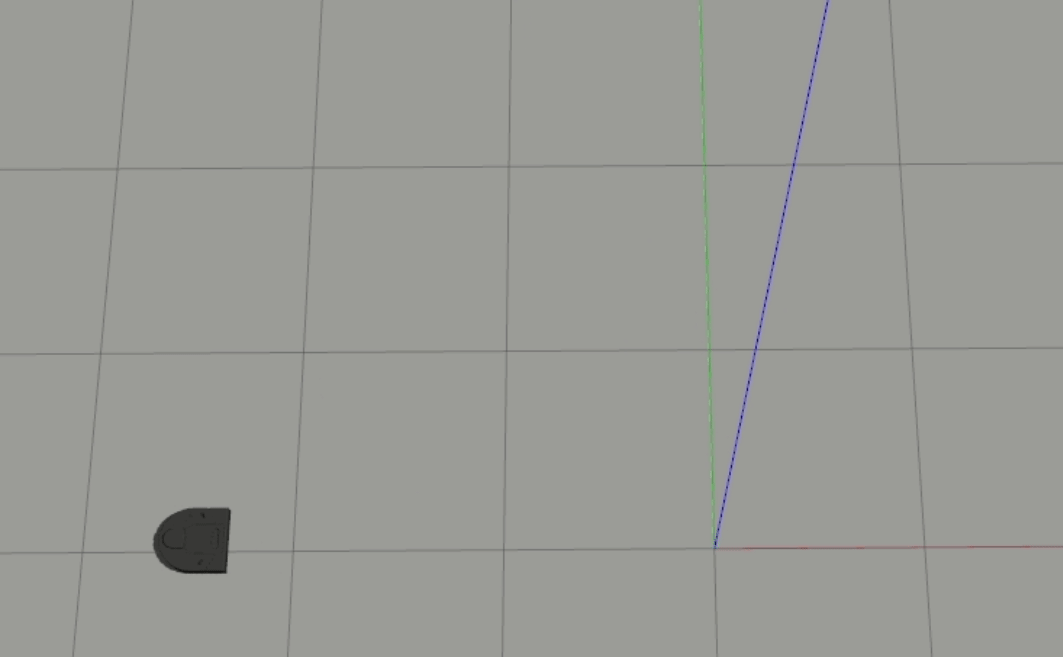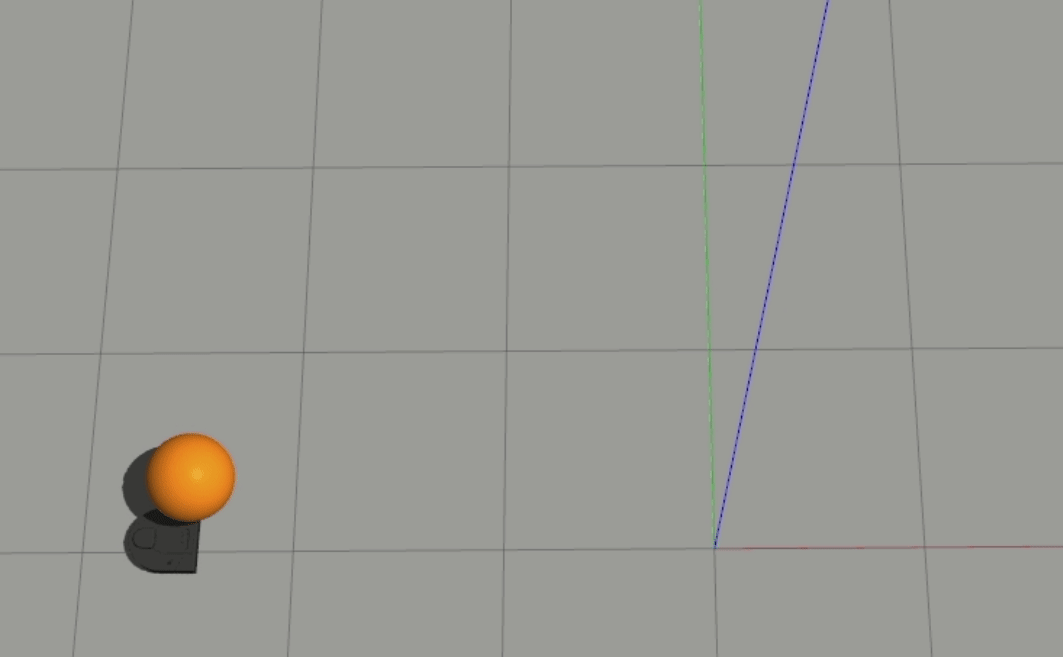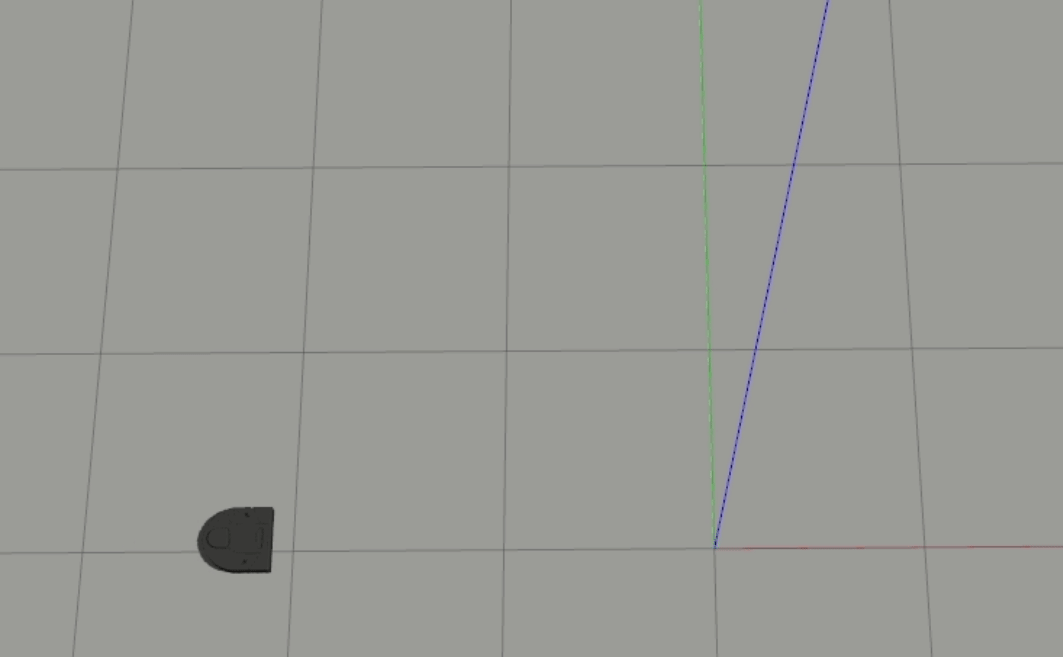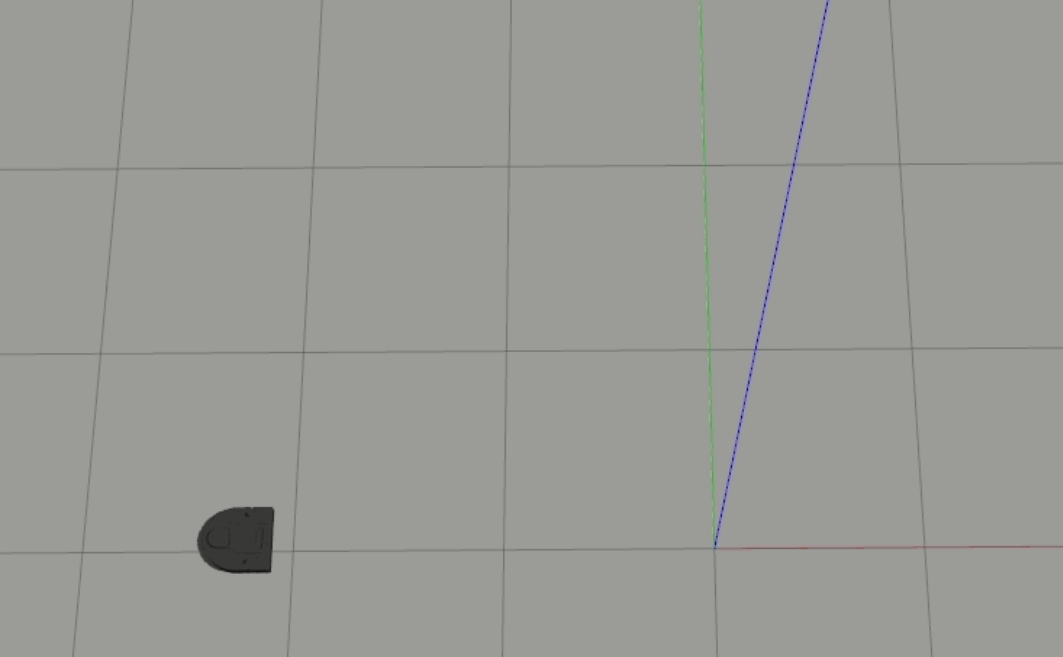
In both of these cases, the robot doesn’t react to the ball headed straight towards it until it almost gets hit. For our 1-layer model, we can look at the weights to understand why this is happening - the px value is the strongest weight (i.e. it has the largest magnitude), which means that the difference between the ball and the robot’s x position is the biggest driver to the robot’s behavior. When the ball is moving straight towards the robot, however, the difference in their x positions is essentially 0, which results in the robot getting hit.
This also results in some interesting behavior when a ball is coming from one side of the robot but is headed to the opposite side.
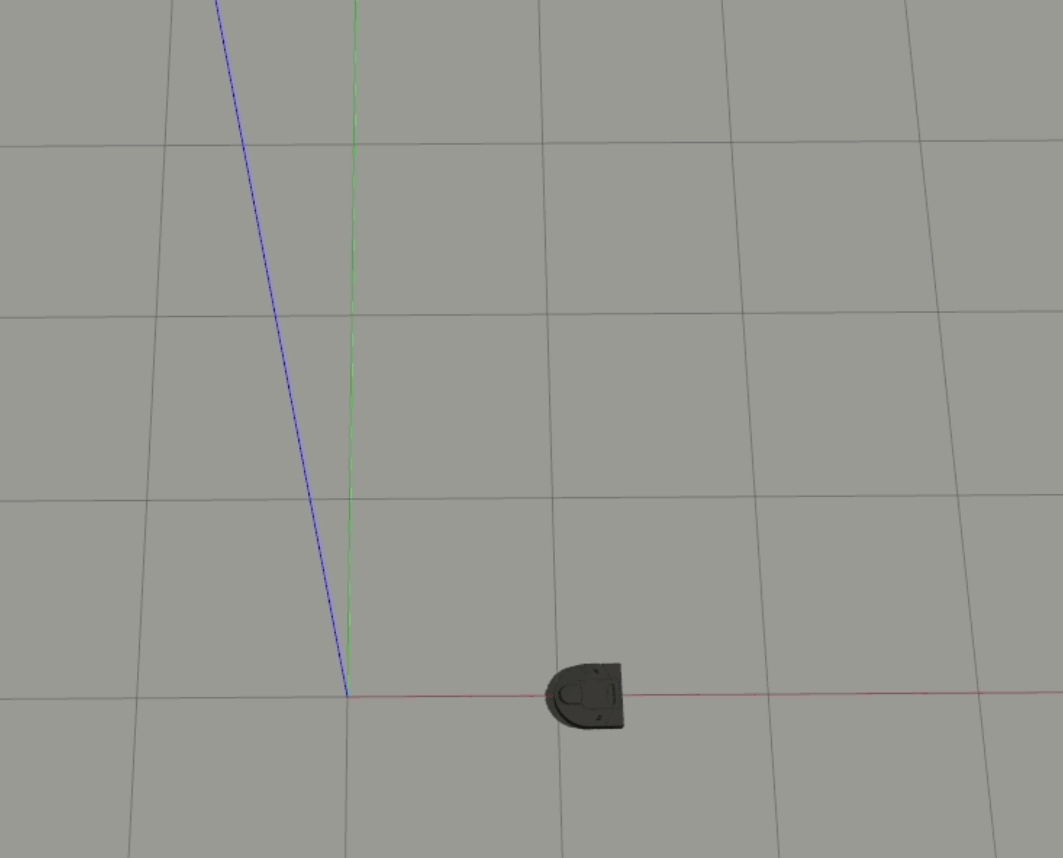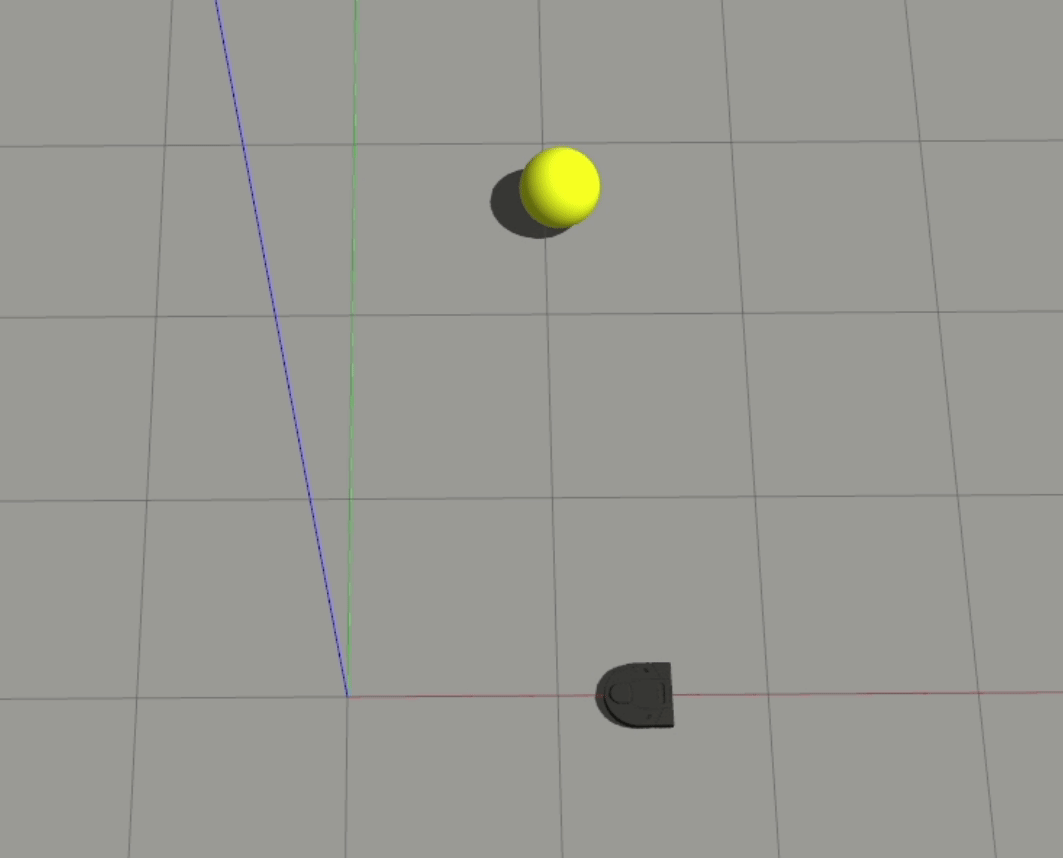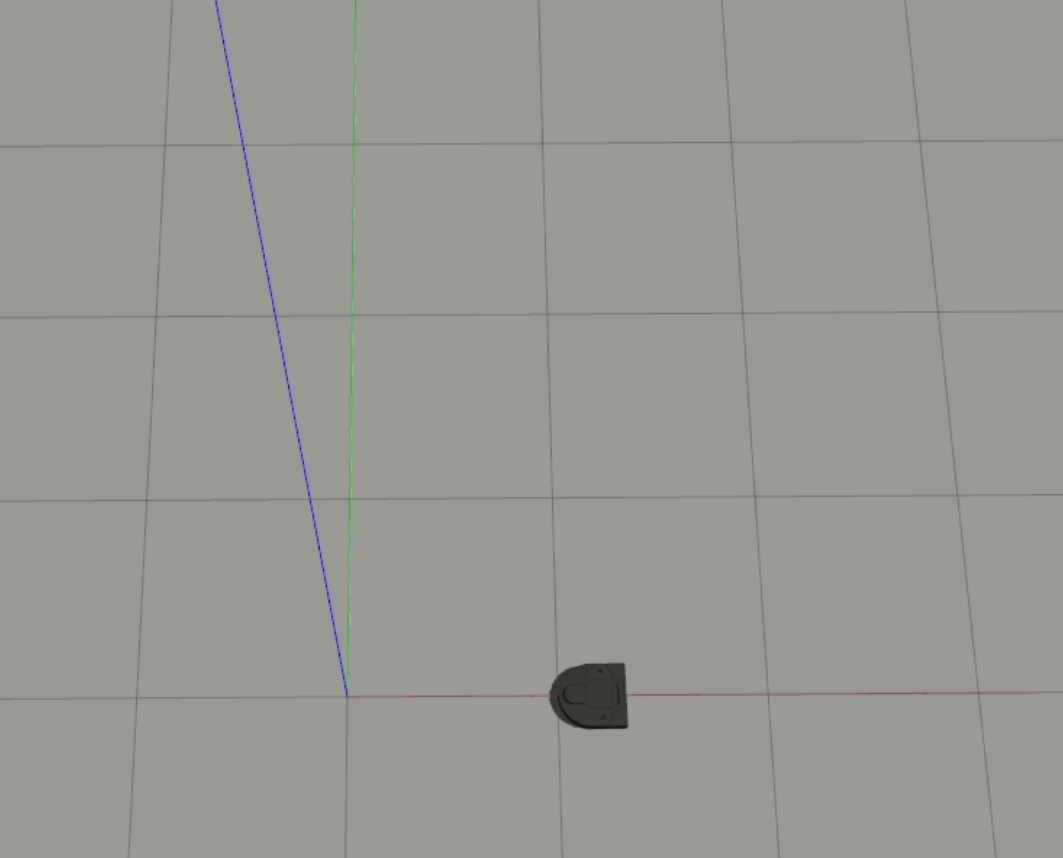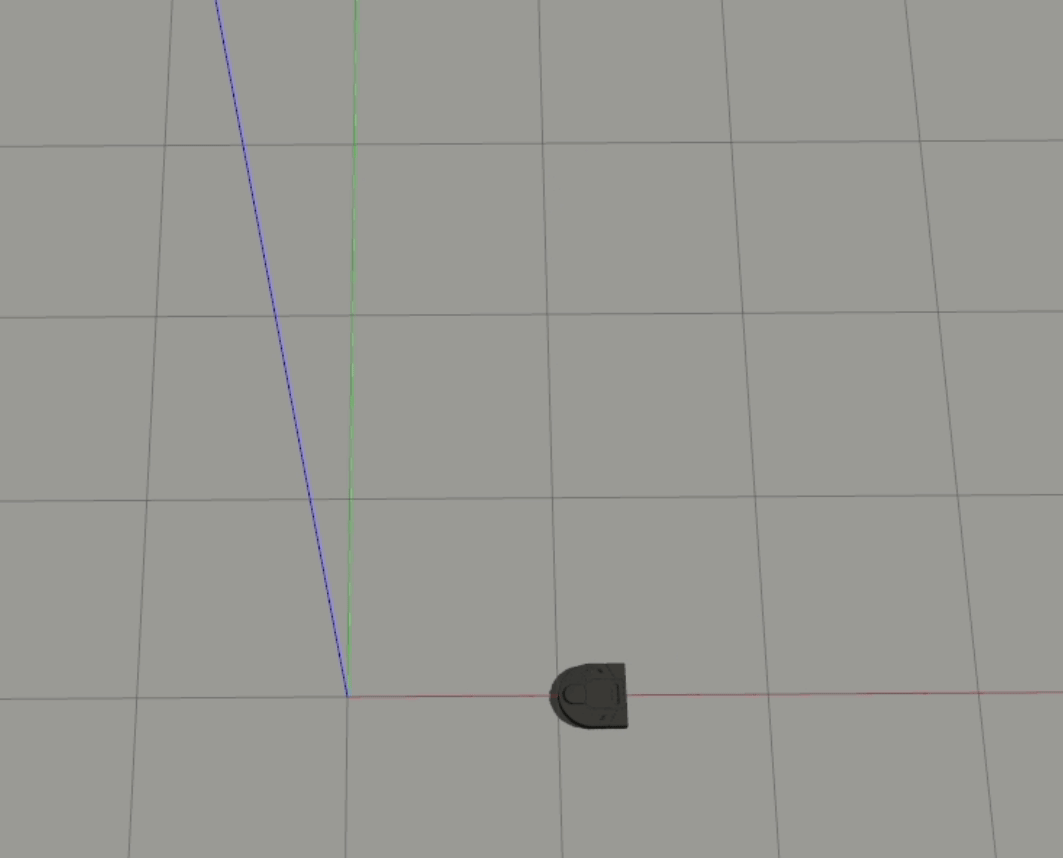
In these “diagonal” cases, the robot initially moves forward since the ball is behind it, but when it crosses the robot’s y-axis, the robot begins to move backwards since the ball is now in front of it. Although it is unlikely that the 1-layer model would be able to encode this case in a more intelligent manner, with lots of data on this specific edge case, a model with more layers should be able to handle this situation.
Although we can’t easily understand the weights for the multi-layer model, based on the similarities between the two models, we can infer that the multi-layer model learned similar features as the 1-layer model. It’s also interesting to see that the multi-layer model was able to learn how to handle certain head-on cases
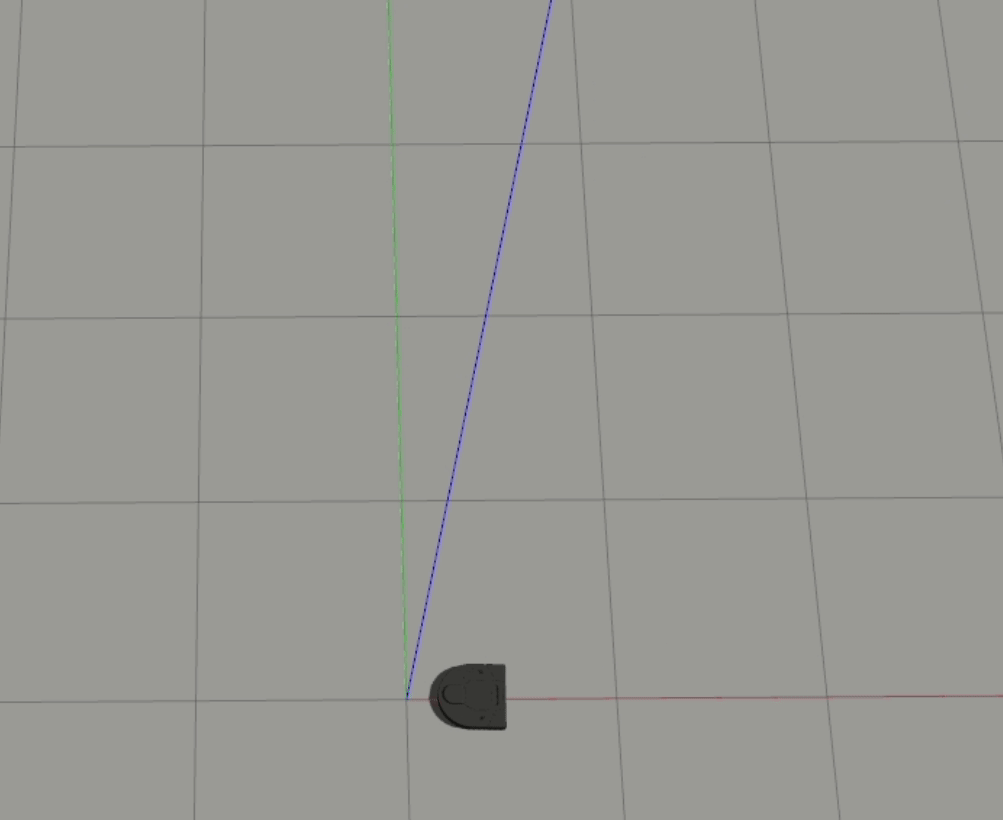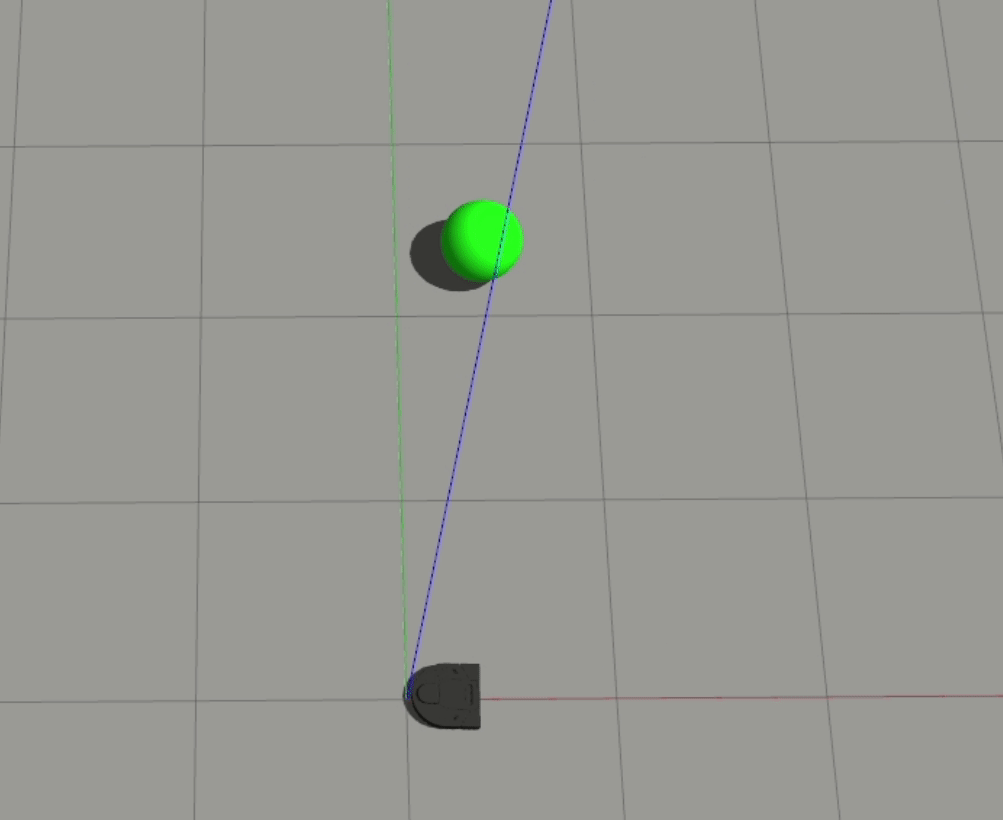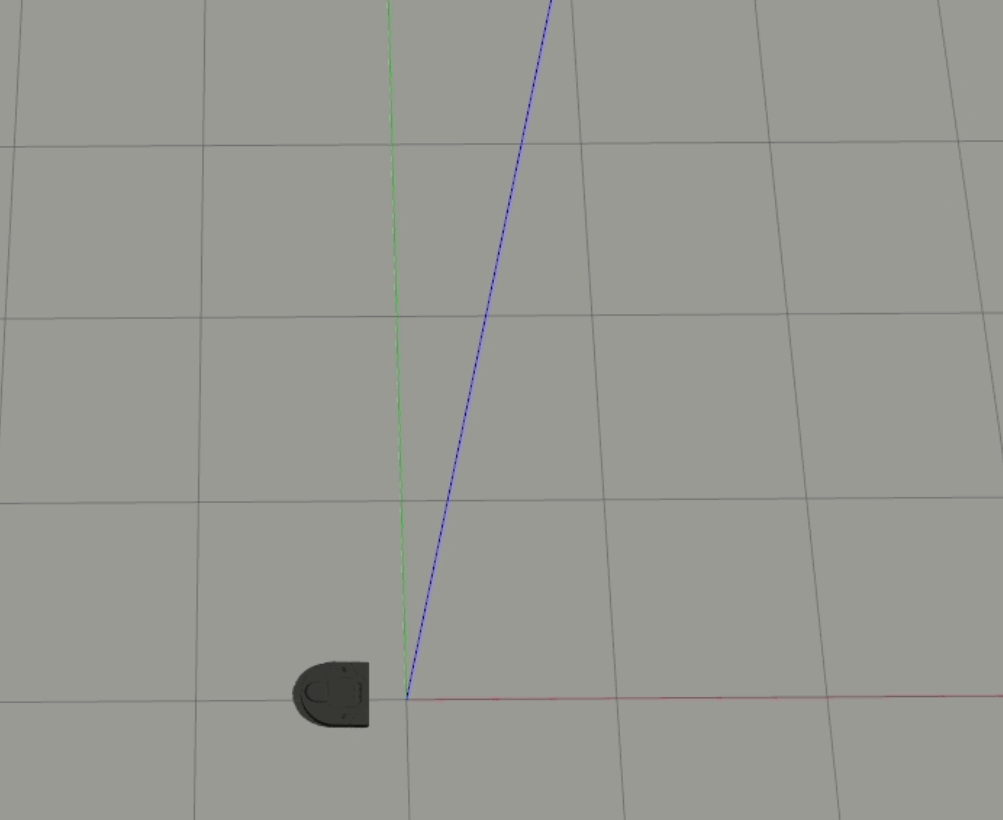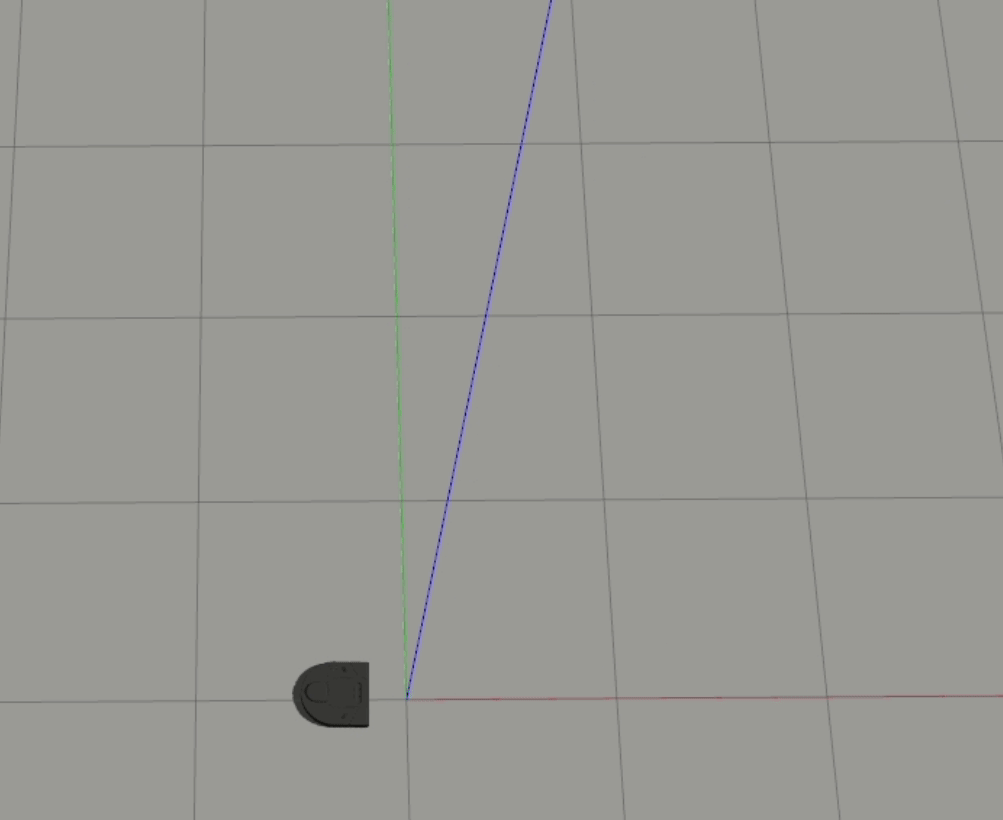 With the data we’re currently giving the model, head-on cases are challenging since our training data is inconsistent for these cases - sometimes, I’d train it to take a hard right, and other times I’d train it to take a hard left. A potential improvement on this in the future would be to train the direction and magnitude of the robot command separately, which might help it figure out this edge case.
With the data we’re currently giving the model, head-on cases are challenging since our training data is inconsistent for these cases - sometimes, I’d train it to take a hard right, and other times I’d train it to take a hard left. A potential improvement on this in the future would be to train the direction and magnitude of the robot command separately, which might help it figure out this edge case.
That’s all for this post folks! Thanks for reading